|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese|
Lecture notes, cheat sheets
Database. Basic relationships (most important)
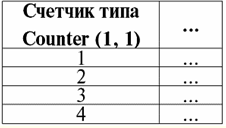
Directory / Lecture notes, cheat sheets Table of contents (expand) Lecture number 7. Basic relations As we already know, databases are like a kind of container, the main purpose of which is to store data presented in the form of relationships. You need to know that, depending on their nature and structure, relationships are divided into: 1) basic relationships; 2) virtual relationships. Base view relationships contain only independent data and cannot be expressed in terms of any other database relationships. In commercial database management systems, basic relationships are usually referred to simply as tables in contrast to representations corresponding to the concept of virtual relations. In this course, we will consider in some detail only the basic relationships, the main techniques and principles of working with them. 1. Basic data types Data types, like relationships, are divided into basic и virtual. (We will talk about virtual data types a little later; we will devote a separate chapter to this topic.) Basic data types - these are any data types that are initially defined in database management systems, that is, present there by default (as opposed to a user-defined data type, which we will analyze immediately after passing through the base data type). Before proceeding to the consideration of the actual basic data types, we list what types of data there are in general: 1) numerical data; 2) logical data; 3) string data; 4) data defining the date and time; 5) identification data. By default, database management systems have introduced several of the most common data types, each of which belongs to one of the listed data types. Let's call them. 1. In numerical data type is distinguished: 1) Integer. This keyword usually denotes an integer data type; 2) Real, corresponding to the real data type; 3) Decimal(n, m). This is a decimal data type. Moreover, in the notation n is a number that fixes the total number of digits of the number, and m shows how many characters of them are after the decimal point; 4) Money or Currency, introduced specifically for convenient data representation of the monetary data type. 2. In logical data type usually allocate only one basic type, this is Logical. 3. String the data type has four basic types (meaning, of course, the most common ones): 1) Bit(n). These are bit strings with fixed length n; 2) Varbit(n). These are also strings of bits, but with a variable length not exceeding n bits; 3) Char(n). These are character strings with constant length n; 4) Varchar(n). These are character strings, with a variable length not exceeding n characters. 4. Type date and time includes the following basic data types: 1) Date - date data type; 2) Time - data type expressing the time of day; 3) Date-time is a data type that expresses both date and time. 5. Identificational The data type contains only one type included by default in the database management system, and that is GUID (Globally Unique Identifier). It should be noted that all basic data types can have variants of different data representation ranges. To give an example, variants of the four-byte integer data type can be eight-byte (bigint) and two-byte (smallint) data types. Let's talk separately about the basic GUID data type. This type is intended to store sixteen-byte values of the so-called globally unique identifier. All different values of this identifier are automatically generated when a special built-in function is called NewId(). This designation comes from the full English phrase New Identification, which literally means "new identifier value". Each identifier value generated on a particular computer is unique within all manufactured computers. The GUID identifier is used, in particular, to organize database replication, i.e., when creating copies of some existing databases. Such GUIDs can be used by database developers along with other basic types. An intermediate position between the GUID type and other base types is occupied by another special base type - the type counter. A special keyword is used to designate data of this type. Counter(x0, ∆x), which literally translates from English and means "counter". Parameter x0 specifies the initial value, and Δx - increment step. Values of this Counter type are necessarily integers. It should be noted that working with this basic data type includes a number of very interesting features. For example, values of this Counter type are not set, as we are used to when working with all other data types, they are generated on demand, much like for values of the globally unique identifier type. It is also unusual that the counter type can only be specified when defining the table, and only then! This type cannot be used in code. You also need to remember that when defining a table, the counter type can only be specified for one column. Counter data values are automatically generated when rows are inserted. Moreover, this generation is carried out without repetition, so that the counter will always uniquely identify each line. But this creates some inconvenience when working with tables containing counter data. If, for example, the data in the relation given by the table changes and they have to be deleted or swapped, the counter values can easily "confuse the cards", especially if an inexperienced programmer is working. Let us give an example illustrating such a situation. Let the following table representing some relation be given, in which four rows are entered:
The counter automatically gave each new line a unique name. And now let's remove the second and fourth lines from the table, and then add one additional line. These operations will result in the following transformation of the source table:
Thus, the counter removed the second and fourth lines along with their unique names, and did not "reassign" them to new lines, as one might expect. Moreover, the database management system will never allow you to change the value of the counter manually, just as it will not allow you to declare several counters in one table at the same time. Typically, the counter is used as a surrogate, i.e., an artificial key in the table. It is interesting to know that the unique values of a four-byte counter at a generation rate of one value per second will last more than 100 years. Let's show how it's calculated: 1 year = 365 days * 24 h * 60 s * 60 s < 366 days * 24 h * 60 s * 60 s < 225 with. 1 second > 2-25 year. 24*8 values / 1 value/second = 232 c > 27 year > 100 years. 2. Custom data type A user-defined data type differs from all base types in that it was not originally built into the database management system, it was not declared as a default data type. This type can be created by any user and database programmer in accordance with their own requests and requirements. Thus, a user-defined data type is a subtype of some base type, that is, it is a base type with some restrictions on the set of allowed values. In pseudocode notation, a custom data type is created using the following standard statement: Create subtype subtype name Type base type name As subtype constraint; So, in the first line, we must specify the name of our new, user-defined data type, in the second - which of the existing basic data types we took as a model, creating our own, and, finally, in the third - those restrictions that we need to add to the existing ones restrictions on the set of values of the base data type - sample. Subtype constraints are written as a condition dependent on the name of the subtype being defined. To better understand how the Create statement works, consider the following example. Suppose we need to create our own specialized data type, for example, to work in the mail. This will be the type to work with data like zip code numbers. Our numbers will differ from ordinary decimal six-digit numbers in that they can only be positive. Let's write an operator to create the subtype we need: Create subtype Postcode Type decimal(6, 0) As Postcode > 0. Why did we choose decimal(6, 0)? Recalling the usual form of the index, we see that such numbers must consist of six integers from zero to nine. That is why we took the decimal type as the base data type. It is curious to note that, in general, the condition imposed on the base data type, i.e., the subtype constraint, may contain the logical connectives not, and, or, and in general be an expression of any arbitrary complexity. Custom data subtypes defined in this way can be freely used along with other basic data types both in program code and when defining data types in table columns, i.e. basic data types and user data types are completely equal when working with them. In the visual development environment, they appear in lists of valid types along with other basic data types. The likelihood that we may need an undocumented (custom) data type when designing a new database of our own is quite high. Indeed, by default, only the most common data types are sewn into the database management system, suitable, respectively, for solving the most common tasks. When compiling subject databases, it is almost impossible to do without designing your own data types. But, curiously, with equal probability, we may need to remove the subtype we created, so as not to clutter up and complicate the code. To do this, database management systems usually have a special operator built in. drop, which means "remove". The general form of this operator for removing unnecessary custom types is as follows: Drop subtype the name of the custom type; Custom data types are generally recommended for subtypes that are general enough. 3. Default values Database management systems may have the ability to create any arbitrary default values or, as they are also called, defaults. This operation in any programming environment has a fairly large weight, because in almost any task it may be necessary to introduce constants, immutable default values. To create a default in database management systems, the function already familiar to us from the passage of a user-defined data type is used Create. Only in the case of creating a default value, an additional keyword is also used default, which means "default". In other words, to create a default value in an existing database, you must use the following statement: Create default default name As constant expression; It is clear that in place of a constant value when applying this operator, you need to write the value or expression that we want to make the default value or expression. And, of course, we need to decide under what name it will be convenient for us to use it in our database, and write this name in the first line of the operator. It should be noted that in this particular case, this Create statement follows the Transact-SQL syntax built into the Microsoft SQL Server system. So what have we got? We have deduced that the default is a named constant stored in databases, just like its object. In the visual development environment, the defaults appear in the list of highlighted defaults. Here is an example of creating a default. Suppose that for the correct operation of our database it is necessary that a value function in it with the meaning of an unlimited lifetime of something. Then you need to enter in the list of values of this database the default value that meets this requirement. This may be necessary, if only because each time you encounter this rather cumbersome expression in the code text, it will be extremely inconvenient to write it out again. That is why we will use the Create statement above to create a default, with the meaning of an unlimited lifetime of something. Create default "no time limit" As ‘9999-12-31 23: 59:59’ The syntax of the Transact-SQL language has also been used here, according to which the values of constants of type "date - time" (in this case, '9999-12-31 23:59:59') are written as strings of characters of a certain direction. The interpretation of character strings as datetime values is determined by the context in which the strings are used. For example, in our particular case, first the limit value of the year is written in the constant line, and then the time. However, for all their usefulness, defaults, like a user-defined data type, can sometimes also require that they be removed. Database management systems usually have a special built-in predicate, similar to an operator that removes a more user-defined data type that is no longer needed. This is a predicate Drop and the operator itself looks like this: Drop default default name; 4. Virtual Attributes All attributes in database management systems are divided (by absolute analogy with relationships) into basic and virtual. So called base attributes are stored attributes that need to be used more than once, and therefore, it is advisable to save. And, in turn, virtual attributes are not stored, but computed attributes. What does it mean? This means that the values of the so-called virtual attributes are not actually stored, but are calculated through the base attributes on the fly by means of given formulas. In this case, the domains of computed virtual attributes are determined automatically. Let's give an example of a table that defines a relation, in which two attributes are ordinary, basic, and the third attribute is virtual. It will be calculated according to a specially entered formula.
So, we see that the attributes "Weight Kg" and "Price Rub per Kg" are basic attributes, because they have ordinary values and are stored in our database. But the attribute "Cost" is a virtual attribute, because it is set by the formula of its calculation and will not be actually stored in the database. It is interesting to note that, due to their nature, virtual attributes cannot take on default values, and in general, the very concept of a default value for a virtual attribute is meaningless, and therefore not applicable. And you also need to be aware that, although the domains of virtual attributes are determined automatically, the type of calculated values \uXNUMXb\uXNUMXbsometimes needs to be changed from an existing one to some other one. To do this, the language of database management systems has a special Convert predicate, with the help of which the type of the calculated expression can be redefined. Convert is the so-called explicit type conversion function. It is written as follows: Convert (data type, expression); The expression that is the second argument of the Convert function will be calculated and output as such data, the type of which is indicated by the first argument of the function. Consider an example. Suppose we need to calculate the value of the expression "2 * 2", but we need to output this not as an integer "4", but as a string of characters. To accomplish this task, we write the following Convert function: Convert (Char(1), 2 * 2). Thus, we can see that this notation of the Convert function will give exactly the result we need. 5. The concept of keys When declaring the schema of a base relation, declarations of multiple keys can be given. We have encountered this many times before. Finally, the time has come to talk in more detail about what the relation keys are, and not be limited to general phrases and approximate definitions. So, let's give a strict definition of a relation key. Relationship schema key is a subschema of the original schema, consisting of one or more attributes for which it is declared uniqueness condition values in relationship tuples. In order to understand what the uniqueness condition is, or, as it is also called, unique constraint, let's start with the definition of a tuple and the unary operation of projecting a tuple onto a subcircuit. Let's bring them: t = t(S) = {t(a) | a ∈ def( t) ⊆ S} - definition of a tuple, t(S) [S' ] = {t(a) | a ∈ def (t) ∩ S'}, S' ⊆ S is the definition of the unary projection operation; It is clear that the projection of the tuple onto the subschema corresponds to a substring of the table row. So what is a key attribute uniqueness constraint? The declaration of the key K for the schema of the relation S leads to the formulation of the following invariant condition, called, as we have already said, uniqueness constraint and denoted as: Inv < K → S > r(S): Inv < K → S > r(S) = ∀t1, T2 ∈ r(t 1[K]=t2 [K] → t 1(S) = t2(S)), K ⊆ S; So, this uniqueness constraint Inv < K → S > r(S) of the key K means that if any two tuples t1 and t2belonging to the relation r(S) are equal in the projection onto the key K, then this necessarily entails the equality of these two tuples and in the projection onto the entire scheme of the relation S. In other words, all values of the tuples belonging to the key attributes are unique, unique in their respect. And the second important requirement for a relation key is redundancy requirement. What does it mean? This requirement means that no strict subset of the key is required to be unique. On an intuitive level, it is clear that the key attribute is that relation attribute that uniquely and precisely identifies each tuple of the relation. For example, in the following relation given by a table:
the key attribute is the "Gradebook #" attribute, because different students cannot have the same gradebook number, i.e., this attribute is subject to a unique constraint. It is interesting that in the schema of any relation, a variety of keys can occur. We list the main types of keys: 1) simple key is a key consisting of one and no more attributes. For example, in an examination sheet for a specific subject, a simple key is the credit card number, because it can uniquely identify any student; 2) composite key is a key consisting of two or more attributes. For example, a composite key in the list of classrooms is the building number and classroom number. After all, it is not possible to uniquely identify each audience with one of these attributes, and it is quite easy to do this with their totality, that is, with a composite key; 3) superkey is any superset of any key. Therefore, the schema of the relation itself is certainly a superkey. From this we can conclude that any relation theoretically has at least one key, and may have several of them. However, declaring a superkey in place of a regular key is logically illegal, as it involves relaxing the automatically enforced uniqueness constraint. After all, the super key, although it has the property of uniqueness, does not have the property of non-redundancy; 4) primary key is simply the key that was declared first when the base relation was defined. It is important that one and only one primary key be declared. In addition, primary key attributes can never take null values. When creating a base relation in a pseudocode entry, the primary key is denoted primary key and in brackets is the name of the attribute, which is this key; 5) candidate keys are all other keys declared after the primary key. What are the main differences between candidate keys and primary keys? First, there can be several candidate keys, while the primary key, as mentioned above, can only be one. And, secondly, if the attributes of the primary key cannot take Null values, then this condition is not imposed on the attributes of the candidate keys. In pseudocode, when defining a base relation, candidate keys are declared using the words candidate key and in brackets next, as in the case of declaring a primary key, the name of the attribute is indicated, which is the given candidate key; 6) external key is a key declared in a base relation that also refers to a primary or candidate key of the same or some other base relation. In this case, the relationship to which the foreign key refers is called a reference (or parent) attitude. A relation containing a foreign key is called child. In pseudocode, the foreign key is denoted as foreign key, in brackets immediately after these words, the name of the attribute of this relation, which is a foreign key, is indicated, and after that the keyword is written references ("refers to") and specify the name of the base relation and the name of the attribute that this particular foreign key refers to. Also, when creating a base relation, a condition is written for each foreign key, called referential integrity constraint, but we will talk about this in detail later. << Back: SQL language (The Select operator is the basic operator of the structured query language. Unary operations in the structured query language. Binary operations in the structured query language. Cartesian product operation. Inner join operations. Natural join operation. Left outer join operation. Right outer join operation. Full outer join operation ) >> Forward: Creating Basic Relationships (Metalinguistic symbols. An example of creating a base relation in a pseudocode record. Stateful integrity constraints. Referential integrity constraints. The concept of indexes. Modification of base relations)
▪ Legal psychology. Lecture notes ▪ Russian language and culture of speech. Crib
The existence of an entropy rule for quantum entanglement has been proven
09.05.2024 Mini air conditioner Sony Reon Pocket 5
09.05.2024 Energy from space for Starship
08.05.2024
▪ Magnetic resonance imaging of a single atom ▪ New record for longest non-stop flight ▪ Octospot - action camera for diving enthusiasts ▪ TV screen as thin as a sheet of paper ▪ Gardening is one of the best antidepressants
▪ section of the site for those who like to travel - tips for tourists. Article selection ▪ Article by Claude Lévi-Strauss. Famous aphorisms ▪ article What funny day is Internet Day? Detailed answer ▪ article Labor protection reporting
Home page | Library | Articles | Website map | Site Reviews
www.diagram.com.ua |





 See other articles Section
See other articles Section 