|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese|
Lecture notes, cheat sheets
Database. SQL language (most important)
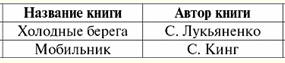
Directory / Lecture notes, cheat sheets Table of contents (expand) Lecture No. 6. SQL language Let us first give a little historical background. The SQL language, designed to interact with databases, appeared in the mid-1970s. (first publications date back to 1974) and was developed by IBM as part of an experimental relational database management system project. The original name of the language is SEQUEL (Structured English Query Language) - only partially reflected the essence of this language. Initially, immediately after its invention and during the primary period of operation of the SQL language, its name was an abbreviation for the phrase Structured Query Language, which translates as "Structured Query Language". Of course, the language was focused mainly on the formulation of queries to relational databases that is convenient and understandable to users. But, in fact, almost from the very beginning, it was a complete database language, providing, in addition to the means of formulating queries and manipulating databases, the following features: 1) means of defining and manipulating the database schema; 2) means for defining integrity constraints and triggers (which will be mentioned later); 3) means of defining database views; 4) means of defining physical layer structures that support the efficient execution of requests; 5) means of authorizing access to relations and their fields. The language lacked the means of explicitly synchronizing access to database objects from the side of parallel transactions: from the very beginning it was assumed that the necessary synchronization was implicitly performed by the database management system. Currently, SQL is no longer an abbreviation, but the name of an independent language. Also, at present, the structured query language is implemented in all commercial relational database management systems and in almost all DBMS that were not originally based on a relational approach. All manufacturing companies claim that their implementation conforms to the SQL standard, and in fact the implemented dialects of the Structured Query Language are very close. This was not achieved immediately. A feature of most modern commercial database management systems that makes it difficult to compare existing dialects of SQL is the lack of a uniform description of the language. Typically, the description is scattered throughout various manuals and mixed with a description of system-specific language features that are not directly related to the structured query language. Nevertheless, it can be said that the basic set of SQL statements, which includes statements for determining the database schema, fetching and manipulating data, authorizing data access, support for embedding SQL in programming languages, and dynamic SQL statements, is well-established in commercial implementations and more or less conforms to the standard. . Over time and work on the Structured Query Language, it has been possible to achieve a standard for a clear standardization of the syntax and semantics of data retrieval statements, data manipulation, and fixing database integrity constraints. Means have been specified for defining the primary and foreign keys of relationships and so-called integrity check constraints, which are a subset of immediately checked SQL integrity constraints. The tools for defining foreign keys make it easy to formulate the requirements of the so-called referential integrity of databases (which we will talk about later). This requirement, common in relational databases, could also be formulated on the basis of the general mechanism of SQL integrity constraints, but the formulation based on the concept of a foreign key is simpler and more understandable. So, taking into account all this, at present, the structured query language is not just the name of one language, but the name of a whole class of languages, since, despite the existing standards, various dialects of the structured query language are implemented in various database management systems, which, of course, have one common basis. 1. The Select statement is the basic statement of the Structured Query Language The central place in the SQL structured query language is occupied by the Select statement, which implements the most demanded operation when working with databases - queries. The Select operator evaluates both relational and pseudo-relational algebra expressions. In this course, we will consider the implementation of only the unary and binary operations of relational algebra that we have already covered, as well as the implementation of queries using the so-called subqueries. By the way, it should be noted that in the case of working with relational algebra operations, duplicate tuples may appear in the resulting relations. There is no strict prohibition against the presence of duplicate rows in relations in the rules of the structured query language (unlike in ordinary relational algebra), so it is not necessary to exclude duplicates from the result. So let's look at the basic structure of the Select statement. It is quite simple and includes the following standard mandatory phrases: Select ... From... Where... ; In place of the ellipsis in each line should be relations, attributes and conditions of a particular database and tasks for it. In the most general case, the basic Select structure should look like this: Select select some attributes from from such a relationship Where with such and such conditions for sampling tuples Thus, we select attributes from the relationship scheme (headings of some columns), while indicating from which relationships (and, as you can see, there may be several) we make our selection and, finally, on the basis of what conditions we stop our choice on certain tuples. It is important to note that attribute references are made using their names. Thus, the following is obtained work algorithm this basic Select statement: 1) the conditions for selecting tuples from the relation are remembered; 2) it is checked which tuples satisfy the specified properties. Such tuples are remembered; 3) the attributes listed in the first line of the basic structure of the Select statement with their values are output. (If we talk about the tabular form of the relationship, then those columns of the table will be displayed, the headings of which were listed as necessary attributes; of course, the columns will not be displayed completely, in each of them only those tuples that satisfied the named conditions will remain.) Consider an example. Let us be given the following relation r1, as a fragment of some bookstore database:
Suppose we are also given the following expression with the Select statement: Select Title of the book, Author of the book from r1 Where Book price > 200; The result of this operator will be the following tuple fragment: (Mobile phone, S. King). (In what follows, we will consider many examples of query implementations using this basic structure and study its application in great detail.) 2. Unary operations in the structured query language In this section, we will consider how the already familiar unary operations of selection, projection, and renaming are implemented in the structured query language using the Select operator. It is important to note that if earlier we could only work with individual operations, then even a single Select statement in the general case allows us to define an entire relational algebra expression, and not just one single operation. So, let's proceed directly to the analysis of the representation of unary operations in the language of structured queries. 1. Sampling operation. The selection operation in SQL is implemented by the Select statement of the following form: Select all attributes from relation name Where selection condition; Here, instead of writing "all attributes", you can use the "*" sign. In Structured Query Language theory, this icon means selecting all attributes from the relation schema. The selection condition here (and in all other implementations of operations) is written as a logical expression with standard connectives not (not), and (and), or (or). Relationship attributes are referred to by their names. Consider an example. Let's define the following relation scheme: academic performance (Gradebook number, Semester, Subject code, Rating, Date); Here, as mentioned earlier, the underlined attributes form the relation key. Let us compose a Select statement of the following form, which implements the unary selection operation: select * From academic performance Where Gradebook # = 100 and Semester = 6; It is clear that as a result of this operator, the machine will display the student's progress with the number of the record of one hundred for the sixth semester. 2. Projection operation. The projection operation in the Structured Query Language is even easier to implement than the fetch operation. Recall that when applying the projection operation, not rows are selected (as when applying the selection operation), but columns. Therefore, it suffices to list the headers of the required columns (i.e., attribute names), without specifying any extraneous conditions. In total, we get an operator of the following form: Select list of attribute names from relation name; After applying this statement, the machine will return those columns of the relation table whose names were specified in the first line of this Select statement. As we mentioned earlier, it is not necessary to exclude duplicate rows and columns from the resulting relation. But if in an order or in a task it is required to eliminate duplicates, you should use a special option of the structured query language - distinct. This option sets the automatic elimination of duplicate tuples from the relation. With this option applied, the Select statement will look like this: Select distinct list of attribute names from relation name; In SQL, there is a special notation for optional elements of expressions - square brackets [...]. Therefore, in its most general form, the projection operation will look like this: Select [distinct] list of attribute names from relation name; However, if the result of applying the operation is guaranteed not to contain duplicates, or duplicates are still admissible, then the option distinct it is better not to specify so as not to clutter up the record, i.e. for reasons of operator performance. Let's consider an example illustrating the possibility of XNUMX% confidence in the absence of duplicates. Let the scheme of relations already known to us be given: academic performance (Gradebook number, Semester, Subject code, Rating, Date). Let the following Select statement be given: Select Gradebook number, Semester, Subject code from academic performance; Here, it is easy to see that the three attributes returned by the operator form the key of the relation. That is why the option distinct becomes redundant, because there are guaranteed to be no duplicates. This follows from a requirement on keys called a unique constraint. We will consider this property in more detail later, but if the attribute is key, then there are no duplicates in it. 3. Rename operation. The operation of renaming attributes in the structured query language is quite simple. Namely, it is embodied in reality by the following algorithm: 1) in the list of attribute names of the Select phrase, those attributes that need to be renamed are listed; 2) the special keyword as is added to each specified attribute; 3) after each occurrence of the word as, the name of the corresponding attribute is indicated, to which it is necessary to change the original name. Thus, taking into account all of the above, the statement corresponding to the operation of renaming attributes will look like this: Select attribute name 1 as new attribute name 1,... from relation name; Let's show how this operator works with an example. Let the relation scheme already familiar to us be given: academic performance (Gradebook number, Semester, Subject code,Rating, Date); Let us have an order to change the names of some attributes, namely, instead of "Account book number" there should be "Account number" and instead of "Score" - "Score". Let's write down what the Select statement that implements this renaming operation will look like: Select record book as Record number, Semester, Subject code, Grade as Score, Date from academic performance; Thus, the result of applying this operator will be a new relationship schema that differs from the original "Achievement" relationship schema in the names of two attributes. 3. Binary operations in the language of structured queries Like unary operations, binary operations also have their own implementation in the structured query language or SQL. So, let's consider the implementation in this language of the binary operations we have already passed, namely, the operations of union, intersection, difference, Cartesian product, natural join, inner and left, right, full outer join. 1. Union operation. In order to implement the operation of combining two relations, it is necessary to use two Select operators simultaneously, each of which corresponds to one of the original relations-operands. And a special operation needs to be applied to these two basic Select statements Union. Considering all of the above, let's write down how the union operation will look like using the semantics of the structured query language: Select list attribute names of relation 1 from relation name 1 Union Select list attribute names of relation 2 from relation name 2; It is important to note that the lists of attribute names of the two relationships being joined must refer to attributes of compatible types and be listed in consistent order. If this requirement is not met, your request cannot be fulfilled and the computer will display an error message. But what is interesting to note is that the names of the attributes themselves in these relationships can be different. In this case, the resulting relation is assigned the attribute names specified in the first Select statement. You also need to know that using the Union operation automatically excludes all duplicate tuples from the resulting relation. Therefore, if you need all duplicate rows to be preserved in the final result, instead of the Union operation, you should use a modification of this operation - the operation Union All. In this case, the operation of combining two relations will look like this: Select list attribute names of relation 1 from relation name 1 Union All Select list attribute names of relation 2 from relation name 2; In this case, duplicate tuples will not be removed from the resulting relation. Using the previously mentioned notation for optional elements and options in Select statements, we write the most general form of the operation of joining two relations in the structured query language: Select list attribute names of relation 1 from relation name 1 Union [All] Select list attribute names of relation 2 from relation name 2; 2. Intersection operation. The operation of intersection and the operation of the difference of two relations in the structured query language are implemented in a similar way (we consider the simplest representation method, since the simpler the method, the more economical, more relevant and, therefore, the most in demand). So, we will analyze the way to implement the intersection operation using keys. This method involves the participation of two Select constructs, but they are not equal (as in the representation of the union operation), one of them is, as it were, a "subconstruction", "subcycle". Such an operator is usually called subquery. So, let's say we have two relationship schemes (R1 and R2), roughly defined as follows: R1 (key,...) and R2 (key,...); When recording this operation, we will also use the special option in, which literally means "in" or (as in this particular case) "contained in". So, taking into account all of the above, the operation of the intersection of two relations using the structured query language will be written as follows: Select * from R1 Where key in (Select key From R2); Thus, we see that the subquery in this case will be the operator in parentheses. This subquery in our case returns a list of key values of the relation R2. And, as follows from our notation of operators, from the analysis of the selection condition, only those tuples of the relation R will fall into the resulting relation1, whose key is contained in the list of keys of the relation R2. That is, in the final relation, if we recall the definition of the intersection of two relations, only those tuples that belong to both relations will remain. 3. Difference operation. As mentioned earlier, the unary operation of the difference of two relations is implemented similarly to the operation of intersection. Here, in addition to the main query with the Select operator, a second, auxiliary query is used - the so-called subquery. But unlike the implementation of the previous operation, when implementing the difference operation, it is necessary to use another keyword, namely not in, which in literal translation means "not in" or (as it is appropriate to translate in our case under consideration) - "is not contained in". So, let, as in the previous example, we have two relationship schemes (R1 and R2), approximately given by: R1 (key,...) and R2 (key,...); As you can see, key attributes are again set among the attributes of these relations. Thus, we get the following form for representing the difference operation in the structured query language: select * from R1 Where key not in (Select key from R2); Thus, only those tuples of the relation R1, whose key is not contained in the list of keys of the relation R2. If we consider the notation literally, then it really turns out that from the relation R1 "subtracted" the ratio R2. From here we conclude that the selection condition in this operator is written correctly (after all, the definition of the difference of two relations is performed) and the use of keys, as in the case of the implementation of the intersection operation, is fully justified. The two uses of the "key method" we have seen are the most common. This concludes the study of the use of keys in the construction of operators representing relations. All remaining binary operations of relational algebra are written in other ways. 4. Cartesian product operation As we remember from the previous lectures, the Cartesian product of two relation-operands is composed as a set of all possible pairs of named values of tuples on attributes. Therefore, in the structured query language, the Cartesian product operation is implemented using a cross join, denoted by the keyword cross join, which literally translates to "cross join" or "cross join". There is only one Select operator in the structure representing the Cartesian product operation in the Structured Query Language and it has the following form: select * from R1 cross join R2 where R1 and R2 - names of initial relations-operands. Option cross join ensures that the resulting relation will contain all the attributes (all, because the first line of the operator has the "*" sign) corresponding to all pairs of relation tuples R1 and R2. It is very important to remember one feature of the implementation of the Cartesian product operation. This feature is a consequence of the definition of the binary operation of the Cartesian product. Recall it: r4(S4) = r1(S1)xr2(S2) = {t(S1 ∪S2) | t[S1] ∈ r1 &t(S2) ∈ r2}, S1 S2= ∅; As can be seen from the above definition, pairs of tuples are formed with necessarily non-intersecting relationship schemes. Therefore, when working in the SQL structured query language, it is invariably stipulated that the initial operand relations should not have matching attribute names. But if these relations still have the same names, the current situation can be easily resolved using the attribute renaming operation, i.e. in such cases, you just need to use the option as, which was mentioned earlier. Let's consider an example in which we need to find the Cartesian product of two relations that have some of their attribute names matching. So, given the following relations: R1 (A, B), R2 (B,C); We see that the R attributes1.B and R2.B have the same names. With this in mind, the Select statement that implements this Cartesian product operation in the structured query language will look like this: Select A, R1.B as B1, R2.B as B2,C from R1 cross join R2; Thus, using the rename option as, the machine will not have "questions" about the matching names of the two original operand relations. 5. Inner join operations At first glance, it may seem strange that we consider the inner join operation before the natural join operation, because when we went through binary operations, everything was the other way around. But by analyzing the expression of operations in the structured query language, one can come to the conclusion that the natural join operation is a special case of the inner join operation. That is why it is rational to consider these operations in that order. So, first, let's recall the definition of the inner join operation that we went through earlier: r1(S1)x P r2(S2) = σ (r1 xr2), St1 ∩ S2 = ∅. For us, in this definition, it is especially important that the considered schemes of relations-operands S1 and S2 must not intersect. To implement the inner join operation in the structured query language, there is a special option inner join, which is literally translated from English as "inner join" or "inner join". The Select statement in the case of an inner join operation will look like this: select * from R1 inner join R2; Here, as before, R1 and R2 - names of initial relations-operands. When implementing this operation, the schemes of relation-operands must not be allowed to cross. 6. Natural join operation As we have already said, the natural join operation is a special case of the inner join operation. Why? Yes, because during the action of a natural join, the tuples of the original operand relations are joined according to a special condition. Namely, by the condition of equality of tuples at the intersection of relations-operands, while with the action of the inner join operation, such a situation could not be allowed. Since the natural join operation we are considering is a special case of the inner join operation, the same option is used to implement it as for the previous considered operation, i.e., the option inner join. But since when compiling the Select operator for the natural join operation, it is also necessary to take into account the condition of equality of the tuples of the original operand relations at the intersection of their schemas, then in addition to the indicated option, the keyword is applied on. Translated from English, it literally means "on", and in relation to our meaning, it can be translated as "subject to". The general form of the Select statement for performing a natural join operation is as follows: select * from relation name 1 inner join relation name 2 on tuple equality condition; Consider an example. Let two relations be given: R1 (A, B, C), R2 (B, C, D); The natural join operation of these relations can be implemented using the following operator: Select A, R1.B, R1.C,D from R1 inner join R2 on R1.B=R2.B and R1.C=R2.C As a result of this operation, the attributes specified in the first line of the Select operator, corresponding to tuples equal at the specified intersection, will be displayed in the result. It should be noted that here we are referring to the common attributes B and C, not just by name. This must be done not for the same reason as in the case of implementing the Cartesian product operation, but because otherwise it will not be clear to which relation they refer. Interestingly, the used wording of the join condition (R1.B=R2.B and R1.C=R2.C) assumes that the shared attributes of the joined Null-value relations are not allowed. This is built into the Structured Query Language system from the very beginning. 7. Left outer join operation The SQL structured query language expression of the left outer join operation is obtained from the implementation of the natural join operation by replacing the keyword inner per keyword left outer. Thus, in the language of structured queries, this operation will be written as follows: select * from relation name 1 left outer join relation name 2 on tuple equality condition; 8. Right outer join operation The expression for a right outer join operation in structured query language is obtained from performing a natural join operation by replacing the keyword inner per keyword right outer. So, we get that in the structured query language SQL, the operation of the right outer join will be written as follows: select * from relation name 1 right outer join relation name 2 on tuple equality condition; 9. Full outer join operation The Structured Query Language expression for a full outer join operation is obtained, as in the previous two cases, from the expression for a natural join operation by replacing the keyword inner per keyword full outer. Thus, in the language of structured queries, this operation will be written as follows: select * from relation name 1 full outer join relation name 2 on tuple equality condition; It is very convenient that these options are built into the semantics of the SQL structured query language, because otherwise each programmer would have to output them independently and enter them into each new database. 4. Using subqueries As could be understood from the material covered, the concept of "subquery" in the structured query language is a basic concept and is quite widely applicable (sometimes, by the way, they are also called SQL queries. Indeed, the practice of programming and working with databases shows that compiling a system of subqueries for solving various related tasks - an activity that is much more rewarding compared to some other methods of working with structured information.Therefore, let's consider an example to better understand the actions with subqueries, their compilation and use. Let there be the following fragment of a certain database, which can be used in any educational institution: Items (Item Code, Item name); Students (record book number, Full Name); Session (Subject code, grade book number, Grade); Let's formulate an SQL query that returns a statement indicating the student's grade book number, last name and initials, and grade for the subject named "Databases". Universities need to receive such information always and in a timely manner, so the following query is perhaps the most popular programming unit using such databases. For convenience, let's additionally assume that the "Last Name", "First Name" and "Patronymic" attributes do not allow Null values and are not empty. This requirement is quite understandable and natural, because the first of the data for a new student to be entered into the database of any educational institution is the data on his last name, first name and patronymic. And it goes without saying that there cannot be an entry in such a database that contains data on a student, but at the same time his name is unknown. Note that the "Item Name" attribute of the "Items" relationship schema is a key, so as follows from the definition (more on this later), all item names are unique. This is also understandable without explaining the representation of the key, because all subjects taught in an educational institution must have and have different names. Now, before we start compiling the text of the operator itself, we will introduce two functions that will be useful to us as we proceed. First, we will need the function Trim, is written Trim ("string"), that is, the argument to this function is a string. What does this function do? They return the argument itself without spaces at the beginning and end of this line, i.e., this function is used, for example, in the cases: Trim ("Bogucharnikov") or Trim ("Maksimenko"), when after or before arguments are worth a few extra spaces. And secondly, it is also necessary to consider the Left function, which is written Left (string, number), i.e., a function of already two arguments, one of which is, as before, a string. Its second argument is a number, it indicates how many characters from the left side of the string should be output in the result. For example, the result of the operation: Left ("Mikhail, 1") + "." + Left ("Zinovievich, 1") will be the initials "M.Z." It is to display the initials of students that we will use this function in our query. So, let's start compiling the desired query. First, let's make a small auxiliary query, which we then use in the main, main query: Select Gradebook number, Grade from Session Where Item code = (Select Item Code from objects Where Item Name = "Databases") as "Estimations" Databases "; Using the as option here means that we have aliased this query "Database Estimates". We did this for the convenience of further work with this request. Next, in this query, a subquery: Select Item Code from objects Where Item Name = "Databases"; allows you to select from the relation "Session" those tuples that relate to the subject under consideration, i.e. to databases. Interestingly, this inner subquery can return no more than one value, since the "Item Name" attribute is the key of the "Items" relationship, i.e. all its values are unique. And the entire query "Scores "Database" allows you to extract from the "Session" relationship data about those students (their gradebook numbers and grades) that satisfy the condition specified in the subquery, i.e. information about the subject called "Database" . Now we will make the main request, using already received results. Select Students. record book number, Trim (Last name) + " " + Left (Name, 1) + "." + Left (Patronymic, 1) + "."as Full name, Estimates "Databases". Grade from Students inner join ( Select Gradebook number, Grade from Session Where Item code = (Select Item Code from objects Where Item Name = "Databases") )as "Estimates" Databases ". on Students. Gradebook # = "Database" grades. Record book number. So, first we list the attributes that will need to be displayed after the query is completed. It should be mentioned that the attribute "Gradebook number" is from the Students relation, from there - the attributes "Last name", "First name" and "Patronymic". True, the last two attributes are not fully deduced, but only the first letters. We also mention the 'Score' attribute from the 'Database Score' query we entered earlier. We select all these attributes from the inner join of the "Students" relation and the query "Database grades". This inner join, as we can see, is taken by us under the condition of equality of the numbers of the record book. As a result of this inner join operation, grades are added to the Students relation. It should be noted that since the attributes "Last Name", "First Name" and "Patronymic" by condition do not allow Null-values and are not empty, the calculation formula that returns the attribute "Name" (Trim (Last name) + " " + Left (Name, 1) + "." + Left (Patronymic, 1) + "."as Full name), respectively, does not require additional checks, is simplified. << Back: Relational algebra. Binary operations (Operations of union, intersection, difference. Operations of Cartesian product and natural join. Properties of binary operations. Variants of join operations. Derived operations. Relational algebra expressions) >> Forward: Basic Relationships (Basic data types. Custom data type. Default values. Virtual attributes. Concept of keys)
▪ Medical statistics. Lecture notes ▪ Hospital therapy. Lecture notes
The existence of an entropy rule for quantum entanglement has been proven
09.05.2024 Mini air conditioner Sony Reon Pocket 5
09.05.2024 Energy from space for Starship
08.05.2024
▪ Artificial photosynthesis system ▪ Laser air defense Skyranger 30 HEL ▪ Virtium 4GB DDR64 VLP RDIMMs ▪ Immunity of pregnant women reacts to the sex of the child
▪ section of the site Cultivated and wild plants. Article selection ▪ article by Jean de La Bruyère. Famous aphorisms ▪ article Who are the Vasiliev brothers? Detailed answer ▪ Zira article. Legends, cultivation, methods of application ▪ article Lubrication of harnesses and harnesses. Simple recipes and tips
Home page | Library | Articles | Website map | Site Reviews
www.diagram.com.ua |


 See other articles Section
See other articles Section 